
Mille-Pensées
Model Summary
Mille-Pensées is a french math reaoning model finetuned on the Mille-Pensées-Dataset from the Qwen2.5-7B-Instruct model. It performs similarly or better than Qwen2.5-Math-7B-Instruct on most French Math Benchmarks while reasoning in french instead of english. It also offers superior performances on English Math and General Benchmarks.
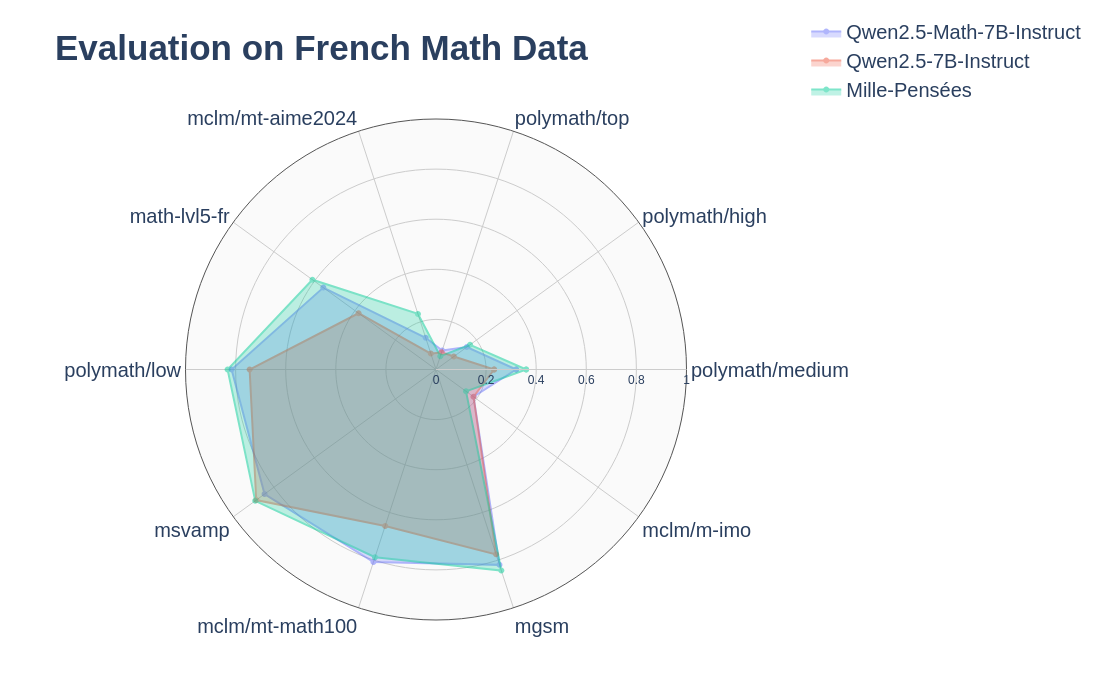
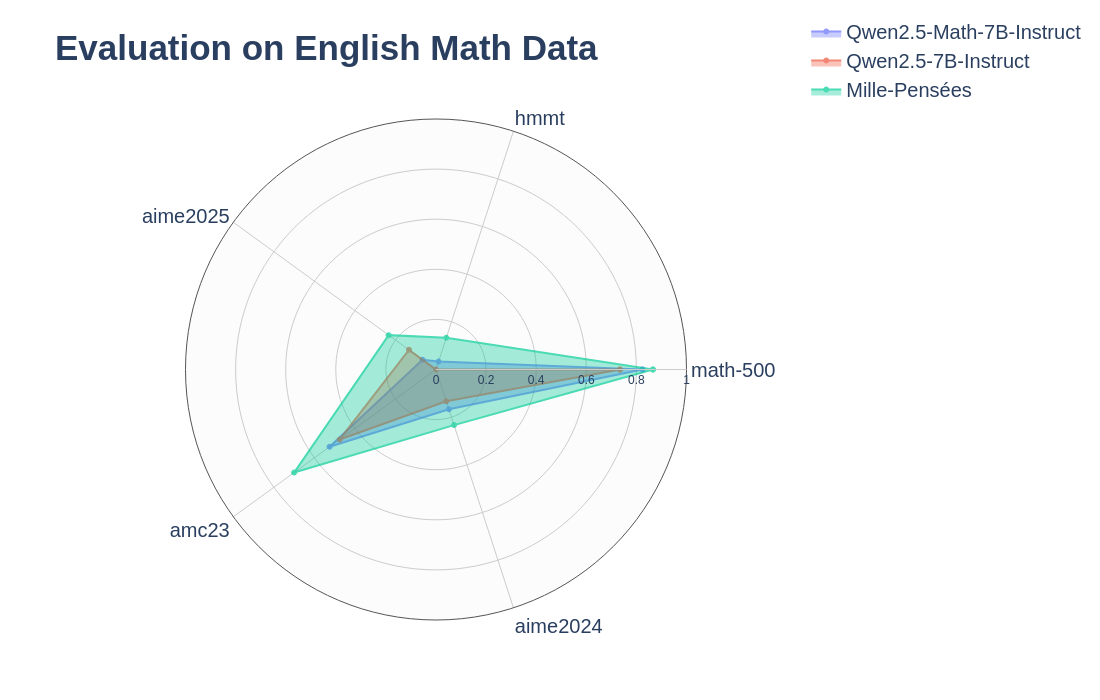
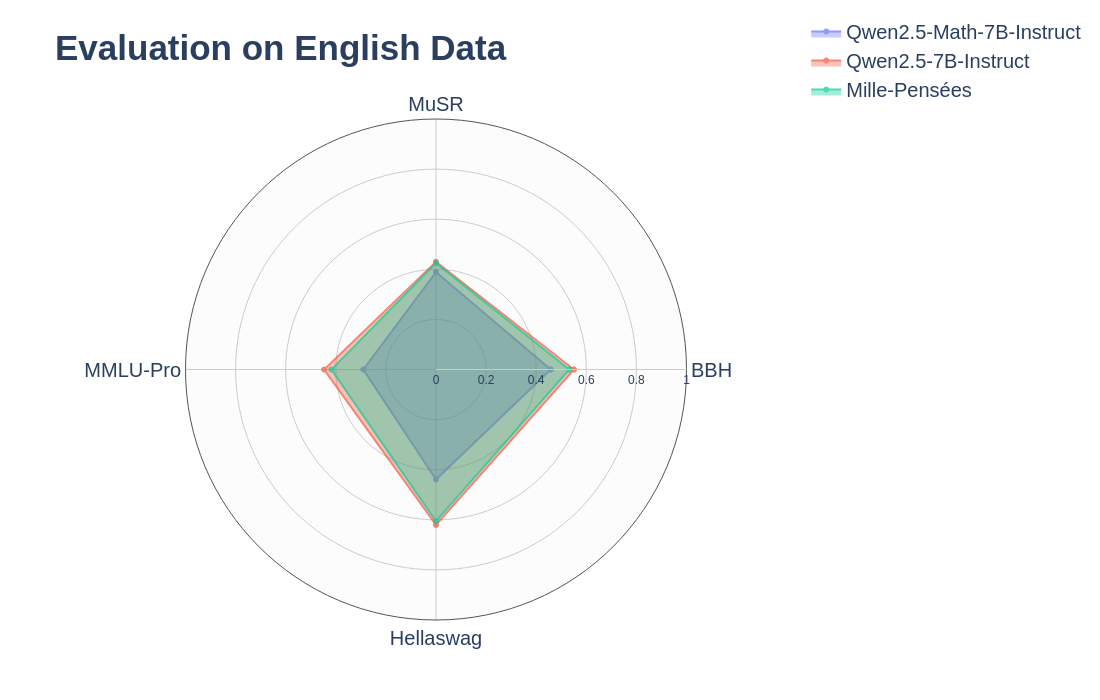
Evaluation was done with vllm and math-verify for Math benchmarks (temperature=0.6, top_p=0.95, top_k=20, min_p=0, presence_penalty=0.5, max_tokens=38192) and lm-evaluation-harness for the general English Benchmarks.
Usage
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_path = "GLauzza/Mille-Pensees"
# Load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path, torch_dtype=torch.float16, device_map="auto"
)
# Example input
messages = [{"role": "user", "content": "Combien vaut 1+1?"}]
input_ids = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors='pt').to("cuda")
generated_ids = model.generate(input_ids, max_new_tokens=38192, temperature=0.6, repetition_penalty=0.5, do_sample=True, eos_token_id=tokenizer.eos_token_id)
response = tokenizer.decode(generated_ids[0], skip_special_tokens=True, clean_up_tokenization_space=True)
print(f"Réponse: {response}")
Training Details
| Parameter | Value |
|---|---|
| Epochs | 3.16 |
| Global Batch Size | 192 |
| Learning Rate | 6e-5 |
| Scheduler | Cosine |
| Optimizer | AdamW |
| Warmup Steps | 100 |
| Weight Decay | 0.0 |
| Max Sequence Length | 18k |
| Sequence Packing | No |
⚠️ Licenses
The base model of this finetuning Qwen2.5-7B-Instruct is licensed under Apache 2.0.
This model was finetuned on the Mille-Pensées-Dataset, which uses multiple datasets licensed under MIT, Apache 2.0 and CC-BY-4.0. However, one of the subsets of the Mille-Pensées-Dataset is from AM-DeepSeek-R1-0528-Distilled and has the following limitation: Developers should strictly limit the use of this project’s open-sourced code, data, models, and related artifacts to research purposes only. Commercial use and any applications that could potentially cause harm are strictly prohibited. The content in this dataset does not reflect the views, beliefs, or endorsements of any individual or institution. The authors disclaim any responsibility for consequences arising from the use, misuse, or interpretation of the dataset and associated materials.
Therefore, if you want to use the Mille-pensées model, you must respect all those licenses and limitations.
Citation Information
This project was provided with computing AI and storage resources by GENCI at IDRIS thanks to the grant 2025-AD011011668R5 on the supercomputer Jean Zay's A100 and H100 partitions.
The authors are affiliated to LORIA, CNRS, Nancy, France.
If you use this dataset, please cite:
@misc{Mille-Pensees,
title={Mille-Pensees},
url={https://huggingface.co/datasets/GLauzza/Mille-Pensees},
author={Gabriel Lauzzana, Imane Ouada, Christophe Cerisara},
month={December},
year={2025}
}
- Downloads last month
- 35