1,I have been trying to fine tune flux1 dev recently. But the results were not ideal. First, let me talk about my training goal: My goal is for the model to follow certain rules and draw according to the trigger word rules. The rules are: 8 lines are grouped together, and the lines in the same group cannot overlap, touch, or cross at any place. All lines can only move from bottom to top in left, right, or diagonal directions, and no downward trajectory is allowed at any position
2,Figure 1 (where the colors no longer represent the same group, but the same material) consists of 6 groups with a total of 7 lines. I hope to use trigger words, 6 sets of 7 lines, and four materials to form a peacock eye when generating reasoning images. Can generate the type shown in the image. From right to left in the figure, it can be understood as:
There are 2 yellow lines, 2 groups.
Green is 3, 2 groups.
Blue is, 1 item, 1 group.
The red one is in the same group as the green two on the right
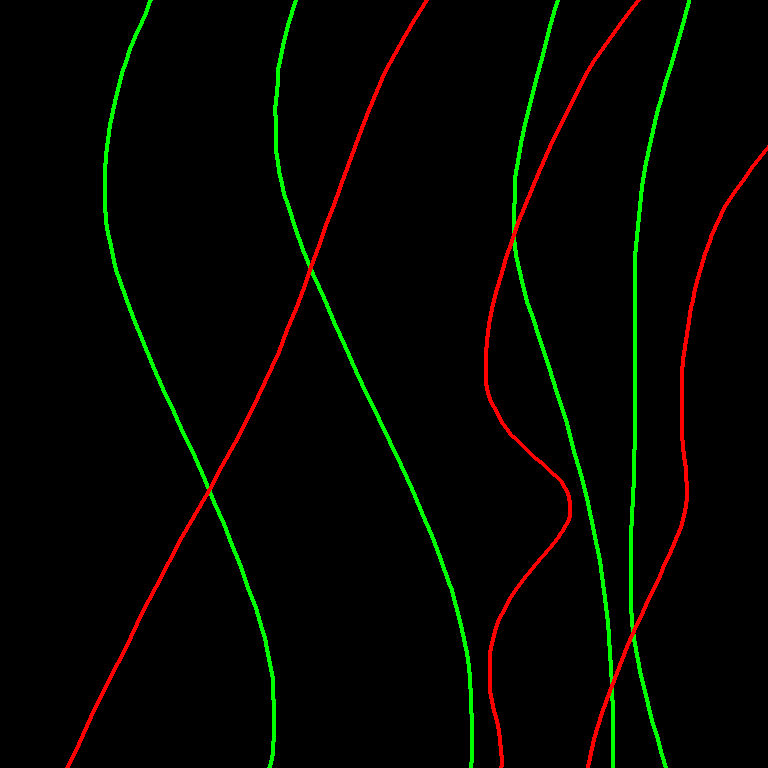
3,Figure 2 is one of my training images (the training image represents the same group with line colors)。caption:
trigger:xiaokangdada,
Generate a lace pattern with:
-
2 groups of lines
-
Total 7 lines
-
Maximum 8 lines per group
-
Group 1: 3 red lines
-
Group 2: 4 green lines
-
Lines move left, right, or diagonally upward
-
No downward movement
-
No branching or disconnection
-
Same group lines do not intersect
-
Different group lines may intersect
-
Black background
4,My device has 230F+16G memory+5060TI-16G. I am using Lora to fine tune FLUX, with a GPU power consumption of 130W and a GPU CHIP POWER DRAW of 50W. Not fully loaded, here are the parameters:
model_train_type = “flux-lora”
model_type = “flux”
pretrained_model_name_or_path = “D:/fluxgym/fluxgym/models/unet/flux1-dev.safetensors”
ae = “D:/fluxgym/fluxgym/models/vae/ae.safetensors”
clip_l = “D:/fluxgym/fluxgym/models/clip/clip_l.safetensors”
t5xxl = “D:/fluxgym/fluxgym/models/clip/t5xxl_fp16.safetensors”
timestep_sampling = “sigmoid”
sigmoid_scale = 1
model_prediction_type = “raw”
discrete_flow_shift = 3.158
loss_type = “l2”
guidance_scale = 1
train_t5xxl = false
apply_t5_attn_mask = true
train_data_dir = “C:/Users/Cinq/Desktop/006/002”
prior_loss_weight = 1
resolution = “768,768”
enable_bucket = false
min_bucket_reso = 256
max_bucket_reso = 2048
bucket_reso_steps = 64
bucket_no_upscale = false
output_name = “qwencaption”
output_dir = “./output”
save_model_as = “safetensors”
save_precision = “bf16”
save_every_n_epochs = 5
save_state = false
max_train_epochs = 15
train_batch_size = 1
gradient_checkpointing = true
gradient_accumulation_steps = 1
network_train_unet_only = true
network_train_text_encoder_only = false
learning_rate = 0.0001
unet_lr = 0.0001
text_encoder_lr = 0.00001
lr_scheduler = “cosine_with_restarts”
lr_warmup_steps = 0
lr_scheduler_num_cycles = 1
optimizer_type = “AdamW8bit”
network_module = “networks.lora_flux”
network_dim = 16
network_alpha = 8
randomly_choice_prompt = false
prompt_file = “”
positive_prompts = “”"
trigger: xiaokangdada,
generate a new vector lace design with the following rules: -
Use exactly 3 color groups (e.g., red, blue, green)
-
Each group has no more than 8 lines
-
Lines within the same group must NOT cross or branch
-
All lines must go only left, right, or up-diagonal — NO downward direction
-
Lines should be continuous and unbroken
-
Different groups are allowed to cross each other
-
Style: abstract technical line art, clean curves from bottom to top
Do not generate any text, textures, or shading.“”"
negative_prompts = “no down”
sample_width = 768
sample_height = 768
sample_cfg = 7
sample_seed = 2333
sample_steps = 24
sample_sampler = “euler_a”
sample_every_n_epochs = 5
log_with = “tensorboard”
logging_dir = “./logs”
caption_extension = “.txt”
shuffle_caption = false
keep_tokens = 0
seed = 44
clip_skip = 2
mixed_precision = “bf16”
sdpa = true
lowram = false
cache_latents = true
cache_latents_to_disk = false
cache_text_encoder_outputs = true
cache_text_encoder_outputs_to_disk = false
persistent_data_loader_workers = true
fp8_base = true
6 questions or requests for help:
6.1 Is my thinking wrong? Is the model incorrect? Is the training chart incorrect? Is the caption incorrect?
6.2 My device cannot run at full capacity, and the training speed is only 7.13/sit. During training, the video memory is 15.5G.CUDA: 100% GPU CHIP POWER DRAW: 50W. It’s obviously too slow. Is the setting incorrect?
6.3 If I want to implement my idea, should I change the model training? Or there are other ways.